

1. Overview
In
this article we’re going to take a look at Lambda timeout errors, monitoring
timeout errors, and how to apply best practices to handle them effectively.

Let’s
first, understand what type of limits are defined by AWS around these
components:
2. AWS Defined Limits

It
means that any API call coming through API Gateway cannot exceed 29 seconds. It
makes sense for most of the APIs except for a few high computational ones.
DynamoDB Streams - has 40,000 write capacity units per table
(in most regions).


It used to be set at 5 minutes, as Lambda was
intended only for small, simple functions with event-driven executions.
However, it proved to be a roadblock for applications like batch applications
and high computation functions which needed more execution time.
Thankfully
AWS increased it, although some purists don't like it as it
defeats the purpose of FaaS being run with small logic only. However, this is a
very high value for regular HTTP APIs and, if not configured at the code level, may
cause timeouts or high cost. We’ll dig deeper into some of those scenarios
shortly. 
That
means it can spin up 1,000 containers for all the functions in an account. If
concurrency is not handled at the function level, it can lead to throttling
issues for all other functions as well.
c. Services
These
configurations also need to be handled for each function, otherwise, it can
cause frequent timeouts.
Now,
let's take a few scenarios and understand how these limits might cause the timeout
errors in a serverless application.
This API is calling a
third-party service to retrieve the data. But for some reason, this third-party
service is not responding. The function has a timeout of 15 minutes, so the
thread will be kept waiting for the response.
However, the threshold limit
for API Gateway is 29 seconds, so the user will receive the timeout error after
29 seconds. Not only is this a poor experience for the user but it will also
result in additional cost.
If the API is not responding,
the function will wait for the response until it reaches the timeout set at the
function level (let's assume 6s), and then timeout. Here one integration
point is causing the whole function to timeout.
- If it is too short, it doesn't give the request the
opportunity to succeed. For example, there's 6s left in the invocation but
we had set timeout to 3s at the integration level.
- If it is too long, the request will timeout at calling
the function. For example. there's the only 5s left in the invocation but we
had set timeout to 6 seconds at the integration level.
Let's talk about the two
general approaches to set timeout values.

Similarly, in the second
approach, if the timeout is set too high for each call, it will cause the
function to timeout without giving a chance for recovery. The function has a 6s
timeout and each integration call have a 5s timeout. So, the whole execution can
take a maximum of 15s + 1s (1s for handling the response at the function
level). In this case, requests are allowed too much time to execute and cause
the function to timeout.
 Solution: To utilize the invocation
time better, set the timeout based on the amount of invocation time left. It
must also account for the time required to perform recovery steps, like
returning a meaningful error or returning a fallback result based on circuit
breaker pattern.
Solution: To utilize the invocation
time better, set the timeout based on the amount of invocation time left. It
must also account for the time required to perform recovery steps, like
returning a meaningful error or returning a fallback result based on circuit
breaker pattern.
Let’s take an example of one
programming language to understand better how to do this:
If Nodejs is the programming
language of your function, Lambda handler does provide context object as
an input. This object has a method, context.getRemainingTimeInMills(), which
returns the approximate remaining execution time of the Lambda function that is
currently executing.
To set the timeout for the
current running function, we can use this code:
var server = app.listen();
And to set the timeout for each API call, we
can use this code:
3. Monitoring Timeout
Errors
 However, CloudWatch doesn't
go deep enough to tell us how much time each downstream call. This information
is required to set a timeout limit at the Integration level. That’s where X-Ray
can be used. It shows the execution time taken by all downstream systems.
However, CloudWatch doesn't
go deep enough to tell us how much time each downstream call. This information
is required to set a timeout limit at the Integration level. That’s where X-Ray
can be used. It shows the execution time taken by all downstream systems.
In the example below, it
shows the execution time of S3 GET (171ms) and S3 PUT (178ms) requests. 
4. Best Practices To Handle
Timeout Errors
- If a function
logic is CPU intensive, apply more memory to reduce the execution time. It
not only saves the cost but reduces timeout errors.
- If a function spends most of its time
on DB operation, there is no point in increasing memory. It doesn't help.
- AWS does charge for lambda usage down
to a fraction of 100ms. So, if average execution time for your lambda function is 110ms, increase the memory to bring it to below 100ms,
otherwise, you’ll be charged for 200ms.
- If your lambda function is taking more
time than the timeout value you wish to have, pay attention to the steps that the function is performing. It might be doing too many things in one function, so you can consider Step Functions
to break the function into smaller pieces.
5. Conclusion
1. Overview
More
and more developers and architects are using AWS Lambda to deploy serverless
functions to control costs and reduce the burden of server management. Due to
the unpredictable nature of end-user demand in today's digital-first world,
Lambda functions can help resolve unplanned scaling issues.
However,
when I talk to these Lambda developers and architects, I hear that they are
struggling with many different types of problems like throttling, timeout, and
slow performances. That's the reason there is a lot of emphases these days to
apply AWS Lambda Best Practices.
In
this article we’re going to take a look at Lambda timeout errors, monitoring
timeout errors, and how to apply best practices to handle them effectively.
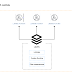
A
Lambda Serverless application is made up of three major components: Event
Source, Lambda Function, and Services (DynamoDB, S3, and the third party).

Let’s
first, understand what type of limits are defined by AWS around these
components:
2. AWS Defined Limits
a. Event Source
AWS API Gateway has a max timeout of 29
seconds for all integration types, which includes Lambda as well.

It
means that any API call coming through API Gateway cannot exceed 29 seconds. It
makes sense for most of the APIs except for a few high computational ones.
DynamoDB Streams - has 40,000 write capacity units per table
(in most regions).

That
means, if DynamoDB is used as a trigger for a Lambda Function, it cannot have
more than 40,000 writes per second. This limit is very high, and if it is used
with the max configuration, most of the downstream system will not be able to
handle that load and could timeout easily.
b. Lambda Function
It used to be set at 5 minutes, as Lambda was
intended only for small, simple functions with event-driven executions.
However, it proved to be a roadblock for applications like batch applications
and high computation functions which needed more execution time.
Thankfully
AWS increased it, although some purists don't like it as it
defeats the purpose of FaaS being run with small logic only. However, this is a
very high value for regular HTTP APIs and, if not configured at the code level, may
cause timeouts or high cost. We’ll dig deeper into some of those scenarios
shortly.
Concurrent Execution - Lambda has a default limit of 1,000 maximum
concurrent executions allowed at an account level.

That
means it can spin up 1,000 containers for all the functions in an account. If
concurrency is not handled at the function level, it can lead to throttling
issues for all other functions as well.
c. Services
Third Party Services - It depends on the downstream system.
These
configurations also need to be handled for each function, otherwise, it can
cause frequent timeouts.
Now,
let's take a few scenarios and understand how these limits might cause the timeout
errors in a serverless application.
Scenario 1
Problem: A REST API implemented
through a Lambda Function is exposed through API Gateway.
This API is calling a
third-party service to retrieve the data. But for some reason, this third-party
service is not responding. The function has a timeout of 15 minutes, so the
thread will be kept waiting for the response.
However, the threshold limit
for API Gateway is 29 seconds, so the user will receive the timeout error after
29 seconds. Not only is this a poor experience for the user but it will also
result in additional cost.
Solution: For APIs, it’s always better
to define your own timeouts at the function level, which should be very short -
around 3-6 seconds. Setting the short timeout will ensure that we don't wait
for an unreasonable time for a downstream response and cause a timeout.
Scenario 2
Problem: REST API is calling multiple
services. It's calling a DynamoDB table to retrieve data, calling an API, and
then storing the data back in the DynamoDB table.
If the API is not responding,
the function will wait for the response until it reaches the timeout set at the
function level (let's assume 6s), and then timeout. Here one integration
point is causing the whole function to timeout.
Solution: For each integration point,
the timeout needs to be set so that the function can handle the timeout error
and process the request with the available data and doesn't waste the execution
time. So here, for all 3 integrations, the timeout limit has to be defined to
handle the response in an effective way.
Scenario 3
Problem: In order to solve the above
two problems, most developers use a fixed timeout limit at the function and
integration level hardcoded in the code/config. However, it doesn't make full
use of the execution time and can cause problems.
- If it is too short, it doesn't give the request the
opportunity to succeed. For example, there's 6s left in the invocation but
we had set timeout to 3s at the integration level.
- If it is too long, the request will timeout at calling
the function. For example. there's the only 5s left in the invocation but we
had set timeout to 6 seconds at the integration level.
Let's talk about the two
general approaches to set timeout values.
In
the first approach, the function timeout limit is set as 6s and for each
integration call, it is set at 2s. Even though the whole function invocation (including
all three calls) can be done within 6s, the API integration call will timeout
as it is not able to perform within 2s. It has not been given the best chance
to complete the request.

Similarly, in the second
approach, if the timeout is set too high for each call, it will cause the
function to timeout without giving a chance for recovery. The function has a 6s
timeout and each integration call have a 5s timeout. So, the whole execution can
take a maximum of 15s + 1s (1s for handling the response at the function
level). In this case, requests are allowed too much time to execute and cause
the function to timeout.

Solution: To utilize the invocation
time better, set the timeout based on the amount of invocation time left. It
must also account for the time required to perform recovery steps, like
returning a meaningful error or returning a fallback result based on circuit
breaker pattern.
Let’s take an example of one
programming language to understand better how to do this:
If Nodejs is the programming
language of your function, Lambda handler does provide context object as
an input. This object has a method, context.getRemainingTimeInMills(), which
returns the approximate remaining execution time of the Lambda function that is
currently executing.
To set the timeout for the
current running function, we can use this code:
var server = app.listen();
server.setTimeout(6000);
And to set the timeout for each API call, we
can use this code:
app.post('/xxx', function (req, res) {
req.setTimeout(
context.getRemainingTimeInMills() - 500 ); // 500ms to account recovery steps
3. Monitoring Timeout
Errors
Lambda automatically monitors
the logs of a function and provide metrics through CloudWatch. CloudWatch
provides Duration metrics which tell us how much time a function is
taking throughout a particular period. It also tells us the Average Duration
which can be used to baseline the function timeout limit.

However, CloudWatch doesn't
go deep enough to tell us how much time each downstream call. This information
is required to set a timeout limit at the Integration level. That’s where X-Ray
can be used. It shows the execution time taken by all downstream systems.
In the example below, it
shows the execution time of S3 GET (171ms) and S3 PUT (178ms) requests.

4. Best Practices To Handle
Timeout Errors
a. Always
use short timeout limits. Set them at 3-6 seconds for API calls, while for
Kinesis, DynamoDB Streams or SQS you should adjust the limits based on the
batch size.
b. Put
monitoring in place using CloudWatch and X-Ray and fine tune the timeout values
as applicable.
c. If
timeouts are unavoidable, either return the response with error code &
error description or use fallback methods. Fallback methods can use
cached data or get data from an alternative source. Spring Cloud provides Hystrix for fallback methods. It
also has the Spring Retry library to apply the retry
logic. Node.js also provides the oibackoff library for retry.
d. DynamoDB
does have a writing capacity defined. If Lambda function concurrent execution
gets increased, it will start timing out if it crosses the writing capacity.
The node-rate-limiter library is available in
Node.js which can be used to control the number of invocations allowed for
DynamoDB.
e. Find
the right balance between performance and cost. To increase performance, Lambda
gives only a single option - increase Memory. More memory equals more
CPU.
- If a function
logic is CPU intensive, apply more memory to reduce the execution time. It
not only saves the cost but reduces timeout errors.
- If a function spends most of its time
on DB operation, there is no point in increasing memory. It doesn't help.
- AWS does charge for lambda usage down
to a fraction of 100ms. So, if average execution time for your lambda function is 110ms, increase the memory to bring it to below 100ms,
otherwise, you’ll be charged for 200ms.
- If your lambda function is taking more
time than the timeout value you wish to have, pay attention to the steps that the function is performing. It might be doing too many things in one function, so you can consider Step Functions
to break the function into smaller pieces.
5. Conclusion
In this article, we have
discussed various scenarios in which timeouts can lead to bad user experience,
not to mention adding cost to your account. So, apply common sense. If a
function is taking more time than allotted, there could well be a problem that
needs proper attention, rather than simply increasing the timeout limit.
Monitoring is the best way to identify these gaps and finetune timeout
configuration.





No comments: