


Overview
Serverless has become the most used deployment pattern for cloud applications. In this field, AWS Lambda is a very well known player. Every developer wants to get his hands dirty with lambda; build a quick function code and run it. Thanks to AWS who gives free 1M requests per month.
However, there are myths that AWS manages the compute so Lambda is hands-off. It handles Scalability, HA, Security, Performance and so on by its own. Lambda is not like an AI robot which learns its own and optimizes its configurations to improve all the Cloud Native metrics. Developers need to pay attention while designing and coding how to make a balance between Cost and Performance. In this blog, I am going to share how we can get the best use of Lambda by understanding how it works.
High Availability
When we run a Lambda function, it by default runs on a VPC which does have internet access. However, it won't have access to any other private VPC. And when I say internet access, it means it can access only S3 and Dynamodb AWS Services. It won't be able to access any other AWS resources (RDS, Elasticsearch, etc..) as they would be running under some VPC.
If a function runs on a Lambda managed VPC, Lambda takes care of its HA running on multiple AZs of that VPC region.
But in most enterprise use case scenarios, we would need access to RDS and other VPC resources. In those cases, we would need to ensure two things:
- Design Lambda for HA by selecting multiple subnets in different AZs.

- If an AZ goes down, other AZs need to have sufficient IP addresses allocated to handle concurrent Lambda requests. (Note, each Lambda execution will require one private IP address to handle the request.) So we need to allocate sufficient IP addresses in a subnet for HA.
Concurrency
AWS Lambda handles the scalability by its own. So why should I be concerned? The truth is nothing comes with infinite resources. Similarly, Lambda also does have concurrency execution limits:
Account level - By default, it is 1000 per region across all the functions.
Function level - By default, it will use the "Unreserved Account Concurrency limit" but that is not a good practice. It can throttle other functions in case one exhausts all the account level concurrency limit. To avoid that, we should always reserve the concurrency limit for each Function so, the impact is isolated to only that function if the number of events surges for any reason.

Note - AWS will always keep an unreserved concurrency pool with a minimum of 100 concurrent execution to process the requests of the functions which didn't set any specific limit. So you would be able to allocate up to 900 only.
What if we are running the Lambda in a dedicated VPC?
In that case, we need to have sufficient IP addresses based on the ENI scalability requirement of the function. You can estimate the approximate ENI capacity with the following formula:
Concurrent executions * (Memory in GB / 3 GB)
Where
- Concurrent execution - is the projected concurrency of the workload. (invocations per second * average execution duration in seconds)
- Memory in GB – The amount of memory configured for the Lambda function.
One more thing to remember while designing concurrency in lambda, we should always consider the limitation of other integrated services like DynamoDB, RDS, etc.. We need to adjust the concurrency limit for the function based on the max connection these services can handle.
Throttling
As discussed in the Concurrency section, any surge of the events for a function can cause throttling if it exceeds the concurrency limit. It means it will not process any new requests. Now, we need to understand how to handle it gracefully else it may cause a huge business impact.
- If lambda invocation is synchronous, it will start receiving 429 error code. It will also receive information if the throttle is at Function level or Account level. Based on that invoking service (e.g. API Gateway) needs to handle the retry.
- If lambda invocation is asynchronous, lambda will try twice before it discards the event. If a function is not able to process the event, we should define DLQ(Dead Letter Queue) using SQS or SNS to debug and process it later. If we forget to define DLQ, messages will be discarded and lost.
- If lambda invocation is a poll based,
- if its stream based (Kinesis), it will keep retrying until the time data expires (up to 7 days).
- if its non-stream based (SQS), it will put the message back to the queue and retry only after the Visibility timeout period expires and keep doing it until it successfully processes or retention period expires.
A Balance Between Memory and Execution Time
In Lambda, memory & CPU go hand-in-hand. If you increase memory, CPU allocation will also increase. Now, if we need to reduce the time of lambda execution, we would try increasing memory/CPU to process it faster. But, here is the catch, if we experiment in detail, we will find that after a certain limit increasing the memory doesn't reduce the execution time but it increases the cost so there is a balance required between performance and the cost involved.
If your application is more on computation logic (CPU Centric), increasing the memory make sense as it will reduce the execution time drastically and save the cost per execution.
Also, AWS does charge for Lambda execution in a fraction of 100ms. If average execution time for your function is 110ms, it will charge you the price of 200ms. So better to increase memory and bring it down to below 100ms. See below example:

There are few open source tools available which claim to help you find the best power configuration. However, I prefer to monitor the usage of the memory and execution time through cloudwatch logs and then adjust the configuration accordingly. Increasing or decreasing a small number makes a big difference in overall AWS cost.
Also, AWS does charge for Lambda execution in a fraction of 100ms. If average execution time for your function is 110ms, it will charge you the price of 200ms. So better to increase memory and bring it down to below 100ms. See below example:

There are few open source tools available which claim to help you find the best power configuration. However, I prefer to monitor the usage of the memory and execution time through cloudwatch logs and then adjust the configuration accordingly. Increasing or decreasing a small number makes a big difference in overall AWS cost.
Performance - Cold Start vs Warm Start
When we invoke the Lambda first time, it does download the code from S3, download all the dependencies, create a container and start the application before it executes the code. This whole duration (except the execution of code) is known as a cold start time. Once the container is up and running, for subsequent Lambda invocation, Lambda is already initialized and it just needs to execute the application logic and that duration is called warm start time.

So should we be worried about the cold start time or warm start time? Well, cold start time takes a significant amount of time as part of full execution. So more emphasis is around reducing that one. However, warm time also can be reduced by following the good coding practice.
Now, let's discuss how can we improve the Lambda performance overall:
- Choose interpreted languages like Nodejs, Python compares to Java, C++ to reduce the cold start time.
- Even if you have to go with Java for a reason, go for Spring Cloud Functions rather than Spring Boot web framework.
- Use the default network environment unless you need a VPC resource with private IP. Because setting up ENI takes significant time and add to the cold start time. With the upcoming release of AWS Lambda, more improvement is expected in this.
- Remove all unnecessary dependencies which are not required to run the function. Keep only the ones which are required at runtime only.
- Use Global/Static variables, Singleton objects - these remain alive until the container goes down. So any subsequent call does not need to reinitialize these variables/objects.
- Define your DB connections at Global level so that it can be reused for subsequent invocation.
- If your Lambda in VPC calling an AWS resource, avoid DNS resolution as it takes significant time. For example, if your Lambda function accesses
an Amazon RDS DB instance in your VPC, launch the instance with the nonpublicly-accessible option. - If you are using Java, prefer to simpler IoC dependency injections like Dagger, Guice rather than Spring-Framework.
- If you are using Java, separate your dependency .jar file from the function's code to speed up the unpacking package process.
- If you are using Nodejs, try to make your Function js file size less than 600 characters and use V8 runtime. V8 optimizer inline the function whose body size is less than 600 characters (including comments).
- If you are using Nodejs, you can use minification or/and uglification of the code to reduce the size of the package and that reduces the time to download the package significantly. In some cases, I have seen the package size reduced from 10MB to 1MB as well.
- Minification - it removes all the spaces/newline characters, comments.
- Uglification - it takes all the variables and obfuscates/simplifies them.
After minification:
After uglification:
You will notice in every blog or documentation mentioning that Lambda execution environment already does have AWS SDK for Nodejs and Python so don't add them in your dependency. It is good for performance improvement but there is a catch. This SDK library will be upgrading regularly with the latest patches and may impact your Lambda behavior so prefer to have your own dependeny management.
Security
- One IAM role per function - One IAM role should be mapped with only one function even though multiple functions need same IAM policies. It helps to ensure the least privilege policies when any enhancement happens for the security policies for the specific function.
- As Lambda would be running on shared VPC, it is not good practice to keep the AWS credential in code.
- In most cases, the IAM execution role is sufficient to connect to AWS services by just using the AWS SDK.
- In cases where a function needs to call the cross-account services, might need the credentials. Then, just use Assume Role API within AWS Security Token Service and retrieve temporary credentials.
- In cases where a function needs long-lived credentials to be stored like DB credentials, access key, either use environment variables with encryption helper or AWS System Manager.
Testability
AWS Lambda is all about your code running in the cloud. So how should we test it in local?
Lambda doesn't provide any endpoint URL to test directly. It always depends on the event source systems to initiate.
- We can use AWS SAM for doing the local testing of the Lambda function. It gives the CLI which provides a Lambda-like execution environment locally. We can get localhost URL for API Gateway which calls the lambda function in local.
- We can use localstack open source project to create a local environment having most of the AWS resources/services available. This can be used to run lambda along with other AWS services. You can integrate AWS SAM and localstack as well as It provides all the services as APIs; running as a Docker container in the backend.
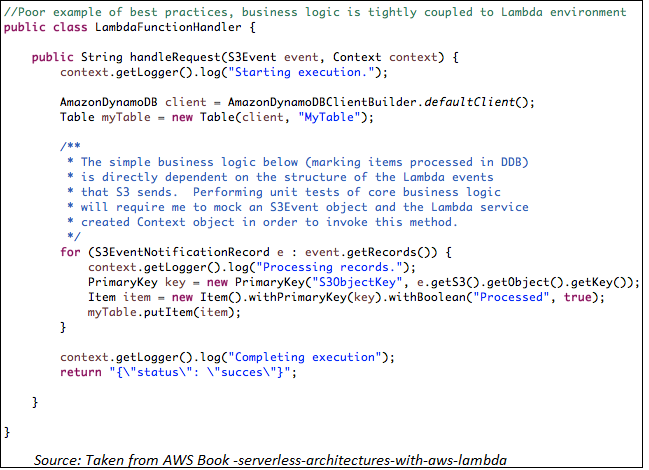
- Put Business logic outside of the Lambda Handler. Handler function should be used just to retrieve the inputs and then pass it to other functions/methods. These functions/methods should parse them into variables related to our application and use it. This will separate the business logic from the handler and it can be tested within the context of objects and functions we have created.
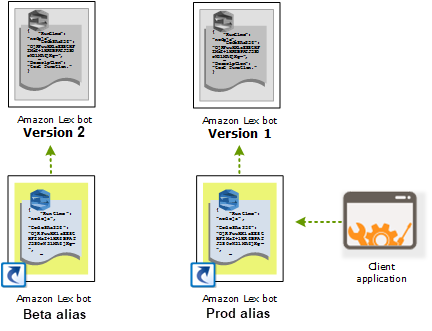
Blue Green Deployment
Lambda has Versioning and Alias features as well. We can publish multiple versions of a function. Each version can be invoked in parallel in a separate container. By default, version would be $LATEST. We can use these versions during development for creating multiple environments like dev/UAT, however, it is not recommended to be used directly for Production env as every time we upload new code, the version will be incremented and clients need to point to the new one. That's where Aliases comes into the picture.
Aliases refer to a particular version of the function. So if the code changes and a newer version is published, event source will still point to the same alias but alias will be updated to refer to the newer version. This helps to plan a Blue/Green Deployment. We can test the newer version with sample events and once it works fine, can be pointed by the Alias to switch the traffic to it. This can be used for rollback to original version also if any issues found.
Monitoring
CloudWatch works very well with Lambda and provides you good details of the lambda execution. Lambda automatically tracks the number of requests, the execution duration per request, and the number of requests resulting in an error and publishes the associated CloudWatch metrics. You can leverage these metrics to set CloudWatch custom alarms as well.
We can also use X-Ray to identify potential bottlenecks in our Lambda execution. The X-Ray can be useful when trying to visualize where we are spending our function’s execution time. It also helps to trace all the downstream systems it connects with the complete flow.
Note: Adding X-Ray in your nodejs code package adds up almost 6MB and that it will also add the compute time of your function execution so use it wisely. Once you are done with your analysis, remove it.
Miscellaneous Tips
- Don't use AWS Lambda Console for developing Production code.
- Code versioning is not available automatically. If you make a bad mistake and hit the Save button, that’s it, your working code is gone forever.
- No integration with GitHub or any other code repository.
- Can’t import modules beyond the AWS SDK. If you need a specific library, you will have to develop your function locally, create a .zip file and upload it to AWS Lambda - which is what you should be doing from the beginning anyways.
- Use AWS SAM or Serverless framework for development.
- Plan for CI/CD for Lambda deployment same as what you do for other deliverables.
- Use Environment Variables (and Parameter Store) to separate code from configuration
Summary
In this article, We talked about many best practices, we can use while designing and deploying Lambda. Depending on the coding language, use cases applied, we can improve its performance. Other Cloud platforms have learned from it and coming up with Serverless on Kubernetes platform. I am eager to get them matured enough to use for Production like applications.
Please do share your opinion through comments on the best practices we can use to run Lambda more effectively.
April 15, 2019
Read more ...



