


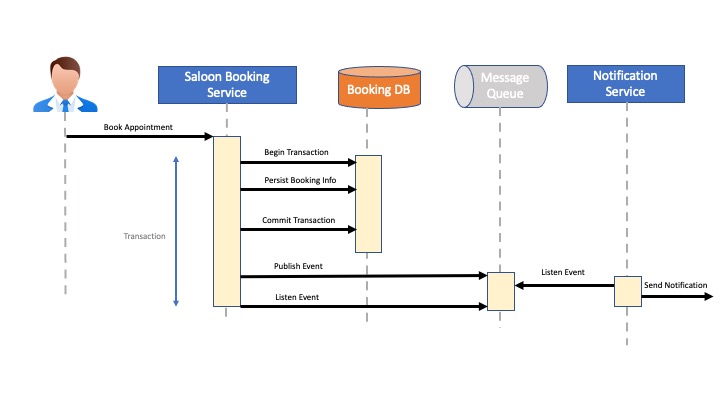
Building an ERP product is a complex process. Many organizations are now trying to develop new ERP solutions using the microservices architecture. Also, the old systems are being migrated to the microservice architecture. Having multiple microservices in the business process would require the Saga pattern for enabling event-driven architecture and distributed transactions. In the Saga pattern, a microservice generally needs to update the business entities and send messages to other microservices. For example, a Salon App manages multiple Salon shops, accepts a booking from the customer and sends a notification to the selected Salon owner with timeslot details.
Now, in this particular use case, both steps have to be part of one atomic process. If the App is able to receive the booking and persist in the DB but sending an event to the Salon owner fails, the customer will go to the shop and there will not be any time reserved for him/her by the Salon owner.
Also, If the DB connection had an issue and the booking is not persisted, the customer would not see the booking confirmation on the screen. However, the event goes successfully to the Salon owner for the booking. Booking will go waste as a customer won't go to the Salon. This is a very bad experience for all the users involved here. So, what's the solution?

Image 1. Use case having a transaction interacting with DB and Queue both
Option 1 - Make Salon Booking Service Also a Subscriber
The first option is making Salon Booking service also a listener to the messaging queue and tracks if the event is published successfully or failed. With this option, now the Salon Booking service can verify both if the message is persisted to the DB and also successfully published to messaging queue. This way, it can mark this whole transaction as successful or fail.
The problem with this option is if the DB persist operation fails but the message is published successfully to MQ, then DB operation will be rolled back but the notification will go to the Salon owner for the booking. You would not want this behaviour in your business process. It will also add a lot of complexity if the user retry to trigger the action and now the DB transaction is successful but we have multiple messages going for notification. Notification service needs to handle it. To make it more complex, if the user decides to change the time slot in the second attempt, now the Notification service will have two messages at different time-slot. Complex logic has to be written to handle many such scenarios.
Option 2 - Transactional Outbox Pattern
This option suggests adding an outbox table in the database and the Salon booking service should send the message to first store it in the database as part of the transaction in which the booking info entity is being persisted. A separate microservice should read this table and send messages to the message queue.

Image 3 - Transaction Outbox Pattern with Polling publisher
This architecture ensures data consistency by persisting all the messages in the outbox table which are supposed to be published. So, in case of MQ failure, Event Handler can have a scheduler to check the pending messages and re-trigger them. In case the DB transaction fails, the process will not go further and would not publish messages as it will error out before itself.
there are different mechanisms to implement the Outbox pattern -
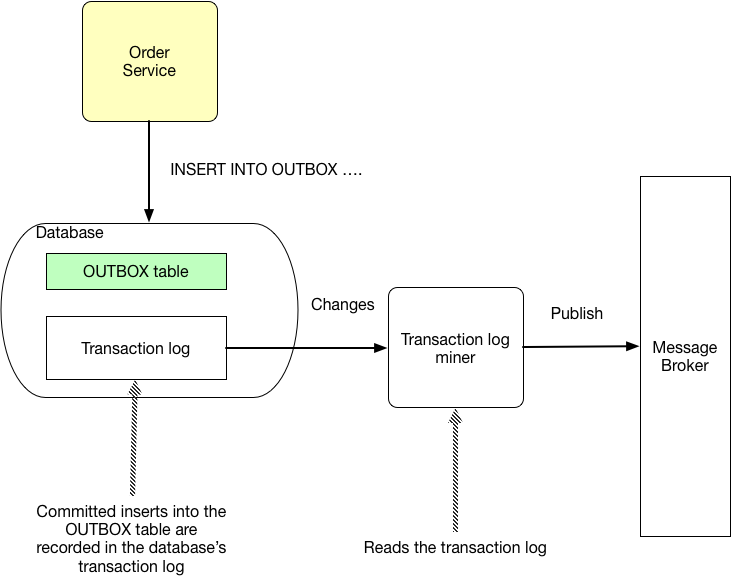
Transaction Log Tailing -
In this implementation, the committed inserts in the Outbox table are recorded in the database's transaction log and using the transaction log minor, we read the logs and publish them to the message queue.
This implementation has a tight coupling with the database as the mechanism to trail the logs depends on the database type -
1. AWS DynamoDB table has streams
2. Postgres has WAL
This implementation has the benefit that we don't need a Two-phase commit (2PC) to ensure data consistency.
Polling Publisher -
This implementation is what we saw in the above diagram (Image 3). In this, the microservice will poll the table for unpublished messages at a fixed rate and process them.
There are two ways to maintain the Outbox records -
1. Delete the record after processing it. However, this may cause the deletion of important information required for audit logging/analysis.
2. Have a column "STATUS" and update the value with "processed", or "not-processed". This ensures proper tracking of the records for analysis in case of production issues.
Outbox pattern can also be used for another use case where microservice would need to publish the message to multiple subscribers with accuracy and data consistency. Also, Change data capture pattern can also be used along with the Outbox pattern. We can cover these use cases in some other article.
In this article, we saw that building a microservice architecture application brings its own challenges, especially for distributed transactions. There are many patterns to solve these problems. And, Outbox pattern is one of those which ensures the DB transaction and events are sent with accuracy and avoid duplicate records as well.
April 22, 2023
Read more ...







{kind=link}