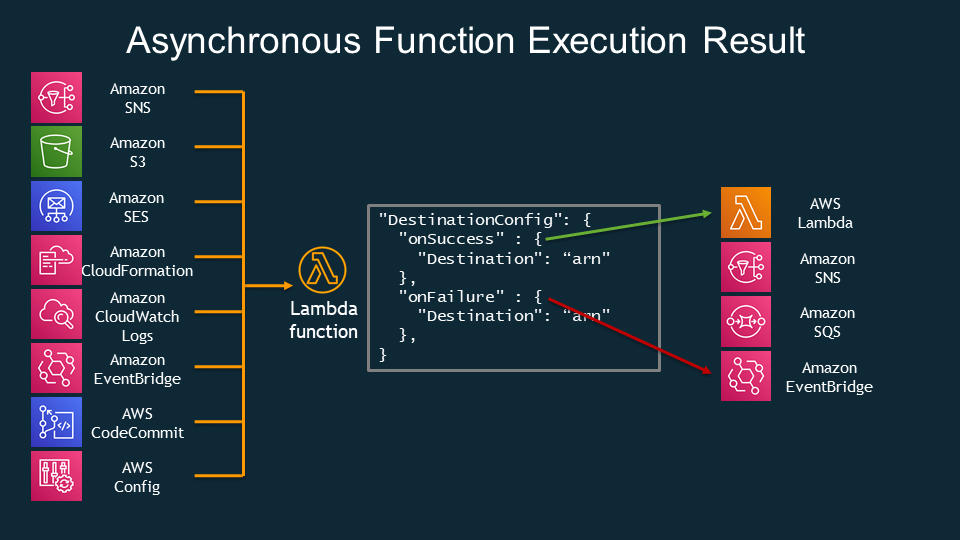
Overview
Spring Cloud Hystrix Project was built as a wrapper on top of the Netflix Hystrix library. Since then, It has been adopted by many enterprises and developers to implement the Circuit Breaker pattern.
In November 2018 when Netflix announced that they are putting this project into maintenance mode, it prompted Spring Cloud to announce the same. Since then, no further enhancements are happening in this Netflix library. In SpringOne 2019, Spring announced that Hystrix Dashboard will be removed from Spring Cloud 3.1 version which makes it
officially dead.
As the Circuit Breaker pattern has been advertised so heavily, many developers have either used it or want to use it, and now need a replacement.
Resilience4j has been introduced to fulfill this gap and provide a migration path for Hystrix users.
Resilience4j
Resilience4j has been inspired by Netflix Hystrix but is designed for Java 8 and functional programming. It is lightweight compared to Hystrix as it has the Vavr library as its only dependency. Netflix Hystrix, by contrast, has a dependency on Archaius which has several other external library dependencies such as Guava and Apache Commons.
A new library always has one advantage over a previous library - it can learn from the mistakes of its predecessor. Resilience4j also comes with many new features:
CircuitBreaker
When a service invokes another service, there is always a possibility that it may be down or having high latency. This may lead to exhaustion of the threads as they might be waiting for other requests to complete. The
CircuitBreaker pattern functions in a similar fashion to an electrical Circuit Breaker:
- When a number of consecutive failures cross the defined threshold, the Circuit Breaker trips.
- For the duration of the timeout period, all requests invoking the remote service will fail immediately.
- After the timeout expires the Circuit Breaker allows a limited number of test requests to pass through.
- If those requests succeed the Circuit Breaker resumes normal operation.
- Otherwise, if there is a failure the timeout period begins again.
RateLimiter
Rate Limiting pattern ensures that a service accepts only a defined maximum number of requests during a window. This ensures that underline resources are used as per their limits and don't exhaust.
Retry
Retry pattern enables an application to handle transient failures while calling to external services. It ensures retrying operations on external resources a set number of times. If it doesn't succeed after all the retry attempts, it should fail and response should be handled gracefully by the application.
Bulkhead
Bulkhead ensures the failure in one part of the system doesn't cause the whole system down. It controls the number of concurrent calls a component can take. This way, the number of resources waiting for the response from that component is limited. There are two types of bulkhead implementation:
- The semaphore isolation approach limits the number of concurrent requests to the service. It rejects requests immediately once the limit is hit.
- The thread pool isolation approach uses a thread pool to separate the service from the caller and contain it to a subset of system resources.
The thread pool approach also provides a waiting queue, rejecting requests only when both the pool and queue are full. Thread pool management adds some overhead, which slightly reduces performance compared to using a semaphore, but allows hanging threads to time out.
Build a Spring Boot Application with Resilience4j
In this article, we will build 2 services - Book Management and Library Management.
In this system, Library Management calls Book Management. We will need to bring Book Management service up and down to simulate different scenarios for the CircuitBreaker, RateLimit, Retry and Bulkhead features.
Prerequisites
- JDK 8
- Spring Boot 2.1.x
- resilience4j 1.1.x (latest version of resilience4j is 1.3 but resilience4j-spring-boot2 has latest version 1.1.x only)
- IDE like Eclipse, VSC or intelliJ (prefer to have VSC as it is very lightweight. I like it more compared to Eclipse and intelliJ)
- Gradle
- NewRelic APM tool ( you can use Prometheus with Grafana also)
Book Management service
- Gradle Dependency
This service is a simple REST-based API and needs standard spring-boot starter jars for web and test dependencies. We will also enable swagger to test the API:
dependencies {
//REST
implementation 'org.springframework.boot:spring-boot-starter-web'
//swagger
compile group: 'io.springfox', name: 'springfox-swagger2', version: '2.9.2'
implementation group: 'io.springfox', name: 'springfox-swagger-ui', version: '2.9.2'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
2. Configuration
The configuration has only a single port as detailed configuration:
server:
port: 8083
- Service Implementation
It has two methods addBook and retrieveBookList. Just for demo purposes, we are using an ArrayList object to store the book information:
@Service
public class BookServiceImpl implements BookService {
List<Book> bookList = new ArrayList<>();
@Override
public String addBook(Book book) {
String message = "";
boolean status = bookList.add(book);
if(status){
message= "Book is added successfully to the library.";
}
else{
message= "Book could not be added in library due to some technical issue. Please try later!";
}
return message;
}
@Override
public List<Book> retrieveBookList() {
return bookList;
}
}
- Controller
Rest Controller has exposed two APIs - one is POST for adding book and the other is GET for retrieving book details:
@RestController
@RequestMapping("/books")
public class BookController {
@Autowired
private BookService bookService ;
@PostMapping
public String addBook(@RequestBody Book book){
return bookService.addBook(book);
}
@GetMapping
public List<Book> retrieveBookList(){
return bookService.retrieveBookList();
}
}
- Test Book Management Service
Build and start the application by using the below commands:
//build application
gradlew build
//start application
java -jar build/libs/bookmanangement-0.0.1-SNAPSHOT.jar
//endpoint url
http://localhost:8083/books
Ensure the service is up and running before moving to build the Library Management service.
Library Management service
In this service, we will be enabling all of the Resilience4j features.
- Gradle Dependency
This service is also a simple REST-based API and also needs standard spring-boot starter jars for web and test dependencies. To enable CircuitBreaker and other resilience4j features in the API, we have added a couple of other dependencies like - resilience4j-spring-boot2, spring-boot-starter-actuator, spring-boot-starter-aop. We need to also add micrometer dependencies (micrometer-registry-prometheus, micrometer-registry-new-relic) to enable the metrics for monitoring. And lastly, we enable swagger to test the API:
dependencies {
compile 'org.springframework.boot:spring-boot-starter-web'
//resilience
compile "io.github.resilience4j:resilience4j-spring-boot2:${resilience4jVersion}"
compile 'org.springframework.boot:spring-boot-starter-actuator'
compile('org.springframework.boot:spring-boot-starter-aop')
//swagger
compile group: 'io.springfox', name: 'springfox-swagger2', version: '2.9.2'
implementation group: 'io.springfox', name: 'springfox-swagger-ui', version: '2.9.2'
// monitoring
compile "io.micrometer:micrometer-registry-prometheus:${resilience4jVersion}"
compile 'io.micrometer:micrometer-registry-new-relic:latest.release'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
- Configuration
Here, we need to do a couple of configurations -
- By default CircuitBreaker and RateLimiter actuator APIs are disabled in spring 2.1.x. We need to enable them using management properties. Refer those properties in the source code link shared at the end of the article. We also need to add the following other properties:
- Configure NewRelic Insight API key and account id
management:
metrics:
export:
newrelic:
api-key: xxxxxxxxxxxxxxxxxxxxx
account-id: xxxxx
step: 1m
- Configure resilience4j CircuitBreaker properties for "add" and "get" service APIs.
resilience4j.circuitbreaker:
instances:
add:
registerHealthIndicator: true
ringBufferSizeInClosedState: 5
ringBufferSizeInHalfOpenState: 3
waitDurationInOpenState: 10s
failureRateThreshold: 50
recordExceptions:
- org.springframework.web.client.HttpServerErrorException
- java.io.IOException
- java.util.concurrent.TimeoutException
- org.springframework.web.client.ResourceAccessException
- org.springframework.web.client.HttpClientErrorException
ignoreExceptions:
- Configure resilience4j RateLimiter properties for "add" service API.
resilience4j.ratelimiter:
instances:
add:
limitForPeriod: 5
limitRefreshPeriod: 100000
timeoutDuration: 1000ms
- Configure resilience4j Retry properties for "get" service API.
resilience4j.retry:
instances:
get:
maxRetryAttempts: 3
waitDuration: 5000
- Configure resilience4j Bulkhead properties for "get" service API.
resilience4j.bulkhead:
instances:
get:
maxConcurrentCall: 10
maxWaitDuration: 10ms
Now, we will be creating a LibraryConfig class to define a bean for RestTemplate to make a call to Book Management service. We have also hardcoded the endpoint URL of Book Management service here. Not a good idea for a production-like application but the purpose of this demo is only to showcase the resilience4j features. For a production app, we may want to use the service-discovery service.
@Configuration
public class LibraryConfig {
Logger logger = LoggerFactory.getLogger(LibrarymanagementServiceImpl.class);
private static final String baseUrl = "https://bookmanagement-service.apps.np.sdppcf.com";
@Bean
RestTemplate restTemplate(RestTemplateBuilder builder) {
UriTemplateHandler uriTemplateHandler = new RootUriTemplateHandler(baseUrl);
return builder
.uriTemplateHandler(uriTemplateHandler)
.build();
}
}
- Service
Service Implementation has methods which are wrapped with @CircuitBreaker,@RateLimiter, @Retry and @Bulkhead annotations These all annotation supports fallbackMethod attribute and redirect the call to the fallback functions in case of failures observed by each pattern. We would need to define the implementation of these fallback methods:
This method has been enabled by CircuitBreaker annotation. So if /books endpoint fails to return the response, it is going to call fallbackForaddBook() method.
@Override
@CircuitBreaker(name = "add", fallbackMethod = "fallbackForaddBook")
public String addBook(Book book){
logger.error("Inside addbook call book service. ");
String response = restTemplate.postForObject("/books", book, String.class);
return response;
}
This method has been enabled by RateLimiter annotation. If the /books endpoint is going to reach the threshold defined in a configuration defined above, it will call fallbackForRatelimitBook() method.
@Override
@RateLimiter(name = "add", fallbackMethod = "fallbackForRatelimitBook")
public String addBookwithRateLimit(Book book){
String response = restTemplate.postForObject("/books", book, String.class);
logger.error("Inside addbook, cause ");
return response;
}
This method has been enabled by Retry annotation. If the /books endpoint is going to reach the threshold defined in a configuration defined above, it will call fallbackRetry() method.
@Override
@Retry(name = "get", fallbackMethod = "fallbackRetry")
public List<Book> getBookList(){
return restTemplate.getForObject("/books", List.class);
}
This method has been enabled by Bulkhead annotation. If the /books endpoint is going to reach the threshold defined in a configuration defined above, it will call fallbackBulkhead() method.
@Override
@Bulkhead(name = "get", type = Bulkhead.Type.SEMAPHORE, fallbackMethod = "fallbackBulkhead")
public List<Book> getBookListBulkhead() {
logger.error("Inside getBookList bulk head");
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return restTemplate.getForObject("/books", List.class);
}
Once the service layer is set up, we need to expose the corresponding REST APIs for each of the methods so that we can test them. For that, we need to create the RestController class.
- Controller
Rest Controller has exposed 4 APIs -
- First one is a POST for adding a book
- Second is again a POST for adding book but this will be used to demo Rate-Limit feature.
- The third one is GET for retrieving book details.
- Forth one is GET API for retrieving book details but enabled with bulkhead feature.
@RestController
@RequestMapping("/library")
public class LibrarymanagementController {
@Autowired
private LibrarymanagementService librarymanagementService;
@PostMapping
public String addBook(@RequestBody Book book){
return librarymanagementService.addBook(book);
}
@PostMapping ("/ratelimit")
public String addBookwithRateLimit(@RequestBody Book book){
return librarymanagementService.addBookwithRateLimit(book);
}
@GetMapping
public List<Book> getSellersList() {
return librarymanagementService.getBookList();
}
@GetMapping ("/bulkhead")
public List<Book> getSellersListBulkhead() {
return librarymanagementService.getBookListBulkhead();
}
}
Now, the code is ready. We have to build and bring it up and running.
- Build and Test Library Management Service
Build and start the application by using the below commands:
//Build
gradlew build
//Start the application
java -jar build/libs/librarymanangement-0.0.1-SNAPSHOT.jar
//Endpoint Url
http://localhost:8084/library
Run Test Scenarios for CircuitBreaker RateLimiter Retry and Bulkhead
CircuitBreaker - Circuit Breaker has been applied to addBook API. To test if it's working, we will stop the Book Management service.
- First, observe the health of the application by hitting http://localhost:8084/actuator/health URL.
- Now stop the Book Management service and hit addBook API of Library Management service using swagger UI
At the first step, It should show the circuit breaker state as "CLOSED". This is Prometheus metrics which we enabled through the micrometer dependency.
After we execute the second step, it will start failing and redirecting to the fallback method.
Once it crosses the threshold, which in this case is 5, it will trip the circuit. And, each call after that will directly go to the fallback method without making an attempt to hit Book Management service. (You can verify this by going to logs and observe the logger statement. Now, we can observe the /health endpoint showing CircuitBreaker state as "OPEN".
{
"status": "DOWN",
"details": {
"circuitBreakers": {
"status": "DOWN",
"details": {
"add": {
"status": "DOWN",
"details": {
"failureRate": "100.0%",
"failureRateThreshold": "50.0%",
"slowCallRate": "-1.0%",
"slowCallRateThreshold": "100.0%",
"bufferedCalls": 5,
"slowCalls": 0,
"slowFailedCalls": 0,
"failedCalls": 5,
"notPermittedCalls": 0,
"state": "OPEN"
}
}
}
}
}
}
We have deployed the same code to PCF (Pivotal Cloud Foundry) so that we can integrate it with NewRelic to create the dashboard for this metric. We have used micrometer-registry-new-relic dependency for that purpose.
Image 2 - NewRelic Insight CircuitBreaker Closed Graph
Rate Limiter - We have created separate API (http://localhost:8084/library/ratelimit) having the same addBook functionality but enabled with Rate-Limit feature. In this case, we would need Book Management Service up and running. With the current configuration for the rate limit, we can have a maximum of 5 requests per 10 seconds.
Once we hit the API for 5 times within 10 seconds of time, it will reach the threshold and get throttled. To avoid throttling, it will go to the fallback method and respond based on the logic implemented there. Below graph shows that it has reached the threshold limit 3 times in the last hour:
Retry - Retry feature enables the API to retry the failed transaction again and again until the maximum configured value. If it gets succeeded, it will refresh the count to zero. If it reaches the threshold, it will redirect it to the fallback method defined and execute accordingly. To emulate this, hit the GET API (http://localhost:8084/library) when Book Management service is down. We will observe in logs that it is printing the response from fallback method implementation.
Bulkhead - In this example, we have implemented the Semaphore implementation of the bulkhead. To emulate concurrent calls, we have used Jmeter and set up the 30 user calls in the Thread group.
We will be hitting GET API () enabled with @Bulkhead annotation. We have also put some sleep time in this API so that we can hit the limit of concurrent execution. We can observe in the logs that it is going to the fallback method for some of the thread calls. Below is the graph for the available concurrent calls for an API:
Summary
In this article, we saw various features that are now a must in a microservice architecture, which can be implemented using one single library resilience4j. Using Prometheus with Grafana or NewRelic, we can create dashboards around these metrics and increase the stability of the systems.