AWS Lambda Layers
AWS Lambda framework is one of the most used services consumed by AWS customers. It is used to build event-driven architecture and serverless architecture applications. It supports various different languages like Java, Python, NodeJS, and many more to build Lambda Function. However, choosing the right language and managing the dependency is very critical as it may affect the size of the package and eventually the load time of the Function while starting instances. AWS Lambda layers is one of the best ways to reduce the size of the deployment packages. These Lambda layers can be for custom runtimes, libraries, or other dependencies.
Diagram placeholder

In this article, we would be going through deep into AWS Lambda framework packaging, Lambda layers working, and best practices around the Lambda layers.
AWS Lambda Framework Packaging
AWS Lambda works with many languages like Java, Python, NodeJS, and so on. A Lambda Function consists of the compiled code, script, and the dependencies it needs to run the code. To deploy this code to the AWS cloud, you need to ZIP the code and it's called a deployment package.
You can upload the package directly to the Lambda framework if the deployment package’s size is less than 50 MB, you must first use Amazon S3 to upload the package and then deploy it to the Lambda service.
Now, the problem with deployment packages is that over a period, it will keep adding more and more dependencies as part of code that causes maintenance overhead. For a small change in a dependency’s code, Function’s code has to be touched, re-packaged, and tested.
Another point is that the more the code you write, the more shared code will be developed that may be used across several Functions. To share it, the AWS Lambda Layers feature has been launched.
How AWS Lambda Layers Work
Lambda Layers provides a mechanism to externally package dependencies that can be shared across multiple Lambda functions. This allows Function to reuse the code already written. Lambda layers reduce lines of code and size of application artifacts.
AWS Lambda Layers can be managed through AWS CLI and APIs. However, AWS has added the support of Layers in AWS SAM framework and AWS SAM CLI that is being used for packaging the Lambda Function code.
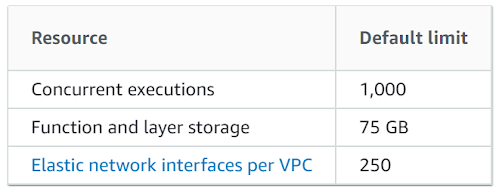
A Lambda Function can use up to 5 layers max. The max size of the total unzipped size of the function and all layers can't exceed 250 MB. You need to keep a watch on AWS Limits that is continuously changing to accommodate all new requirements.

When a Lambda Function ( with a Lambda layer) is invoked, AWS downloads the specified layers and extracts them to the /opt directory on the execution environment of the Function instance. Each runtime then looks for a language-specific (NodeJS, Java, Python, etc..) folder under the /opt directory.
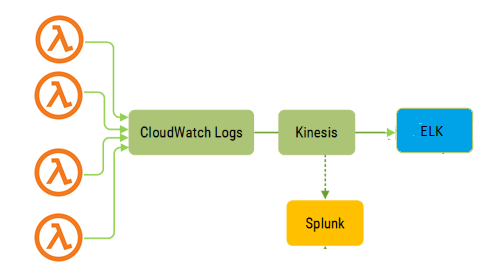
You can create and upload your own Lambda layers and publish it for sharing with others. You can implement an AWS managed layer such as SciPi, or you can grab a third-party layer from an APN Partner or other reliable sources. Below is a typical workflow for a Lambda layer:
Diagram placeholder
Including Library Dependencies in a Lambda Layer
Each Function will have one or more runtime dependencies that can be moved out of the Function code by placing them in a Lambda layer. To include libraries in a layer, place them in one of the folders supported by your runtime, or modify that path variable for your language.
For example: Node.js – nodejs/node_modules, nodejs/node8/node_modules (NODE_PATH)
Lambda runtimes ensure to include /opt directory in paths so that your function code has access to libs that are included in Lambda layers.
AWS Lambda Permission for Layers
AWS provides Identity and Access Management (IAM) to manage access to Functions and Layers. Layer usage permissions are managed on the resource. To configure a function with a layer, you need AWS Lambda permission to call GetLayerVersion on the layer version. You can get this permission by configuring your user policy or from the Function's resource-based policy. A Lambda layer can be added to another account as well by providing permission on your user policy. Also, the owner of the other account must grant your account permission with a resource-based policy.
Below is a command add-layer-version-permission that is used to add the layer usage permission:
aws lambda add-layer-version-permission --layer-name log-sdk-nodejs --statement-id xaccount
--action lambda:GetLayerVersion --principal 110927634125 --version-number 1 --output text
Permission is provided at the layer version level so you have to repeat this step for each time you add a new version for the layer.
How Lambda Layers Work in AWS SAM CLI
AWS SAM and its CLI are used to replicate the Lambda service environment in local and enable testing before moving the code to the AWS cloud. To enable the Lambda layers to support, it downloads all the configured layers and caches them in the local environment. You can use –layer-cache-basedir flag to specify the target directory to store the local cache of the layer.
Downloading of layers happens when the first time you run either sam local invoke or sam local start-lambda or sam local start-api commands. To refresh the layer cache, you can use the –force-image-build flag.
The AWS::Serverless::LayerVersion resource type is used in the SAM template file to create a layer version that you can reference from your function configuration.
Below is an example of a SAM template for a NodeJS application that is using plain-nodejs-lib library as a layer.
AWSTemplateFormatVersion: '2010-09-09'
Transform: 'AWS::Serverless-2016-10-31'
Description: An AWS Lambda application for XRay demo.
Resources:
function:
Type: AWS::Serverless::Function
Properties:
Handler: index.handler
Runtime: nodejs12.x
CodeUri: function/.
Description: Call the AWS Lambda API for XRay demo
Timeout: 5
# Function's execution role
Policies:
- AWSLambdaBasicExecutionRole
- AWSLambdaReadOnlyAccess
- AWSXrayWriteOnlyAccess
Tracing: Active
Layers:
- !Ref libs
libs:
Type: AWS::Serverless::LayerVersion
Properties:
LayerName: plain-nodejs-lib
Description: Dependencies for the plain nodejs app.
ContentUri: lib/.
CompatibleRuntimes:
- nodejs12.x
Things to Remember for Lambda Layers
Though Lambda layers play a great role to distribute your code and share with others, there are few things to keep in mind:
For static languages such as Java, the compiler needs to have all the dependencies at compile time to build the JAR. That won’t be an easy integration.
You need to be careful while using the Lambda layer version shared by third parties as first they might have malware, vulnerabilities; second, you won’t have control on their SDLC so if they plan to remove the version that you are using in production and you have a need to upgrade your code, you won’t get the same layer version in your environment and will cause a failure.
Lambda layers are good when you need to share the same code with multiple Functions in your domain as you would have good control over the versions.
If you have a dependency that is very large in size, you can use layers to reduce the deployment package size and also the time of deployment.
If you are building a custom runtime for Lambda Function, layers is the best way to share it.
Summary
In this article, we looked into the role of AWS Lambda layers in building the Lambda Function code. We also talked about its features, how to enable it, secure it, and apply it using SAM CLI. There are few things we need to keep in mind that this feature has to be used only in special circumstances that we discussed in this article else it may bring overhead in the maintenance of the Function code.